作者:阿里云DataWorks团队
数据生产的稳定性是企业在建设大数据平台时会遇到的第一个问题,对于数仓同学来说,值班是工作的一部分,值班同学的一晚大概是这样的:
凌晨1:30,收到电话告警,机器人自动播报“XX任务已延迟XX分钟,请尽快处理!”
凌晨1:31,起床打开电脑,处理告警问题,1:40、1:50、2:00,电话告警不断轰炸,手机不断震动,前往客厅办公
凌晨2:00,对于上下游任务逻辑不太清楚,拉起一批同学起夜
凌晨3:00,老板被Call醒,打来电话询问情况,沟通后续处理方案
凌晨5:00,所有任务处理完成,等待集群资源计算数
上午7:00,睡眼朦胧,起床前往公司上班
-
上午9:00,刚出电梯口,被业务小二围住追问数据产出时间,并开启一天的工作
可以说,天下数仓同学苦值班久矣!在阿里巴巴内部,当我们在做数据稳定性治理的时候,往往会围绕两个核心指标进行优化,分别是起夜率与基线破线率。
起夜率
指在日常工作中,数仓值班同学需要起来处理问题的天数占比全年天数,如果一个晚上无事发生,数仓同学不需要起夜,我们也引用了游戏中的一个概念,称为平安夜,起夜率相对越低越好。
基线破线率
基线是DataWorks独创的理念,在基线上我们可以为任务设置最晚产出时间。例如当天营收数据,最晚产生时间设置为凌晨2:00,如果这个任务最终产出超过2:00,那么这条基线就破线了,基线破线率同样也是越低越好。
在治理实践中,通常是以下流程:
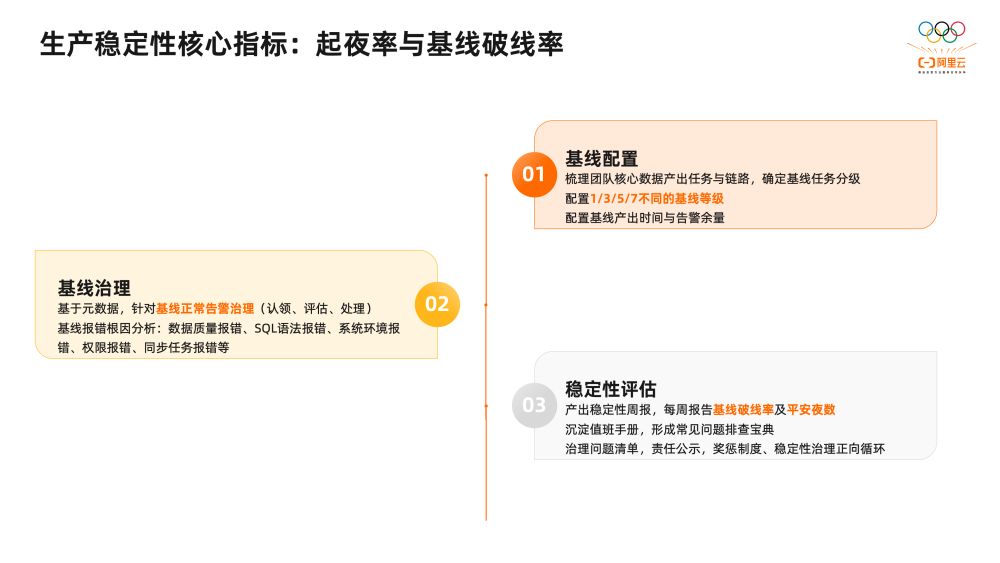
1、基线配置
梳理团队核心数据产出任务与链路,确定基线任务分级,将不同的任务配置1/3/5/7不同的基线等级,同时配置基线产出时间与告警余量。告警余量是一个非常重要的概念,类似抢救时间。例如刚才我们提到的任务产出时间设置为凌晨2:00,如果告警余量设置成1小时,基线会预测任务产出时间,如果时间超过凌晨1:00便会进行告警,方便我们提前知晓核心任务的产出风险。
2、基线治理
基于基线功能以及一些元数据,数仓团队针对基线告警进行治理,包括告警的认领、评估、处理等,同时会针对基线告警进行根因分析,看下是由于什么原因导致的数据稳定性问题,常见的有据质量报错、SQL语法报错、系统环境报错、权限报错、同步任务报错等,进行生产稳定性的根治治理
3、稳定性评估
最终,团队产出稳定性周报,每周报告基线破线率及平安夜数,在值班手册中,也会形成常见问题排查宝典,治理问题清单,将稳定性治理的经验沉淀成团队共同的知识资产,并且进行责任公示,设计奖惩制度、达到稳定性治理正向循环。
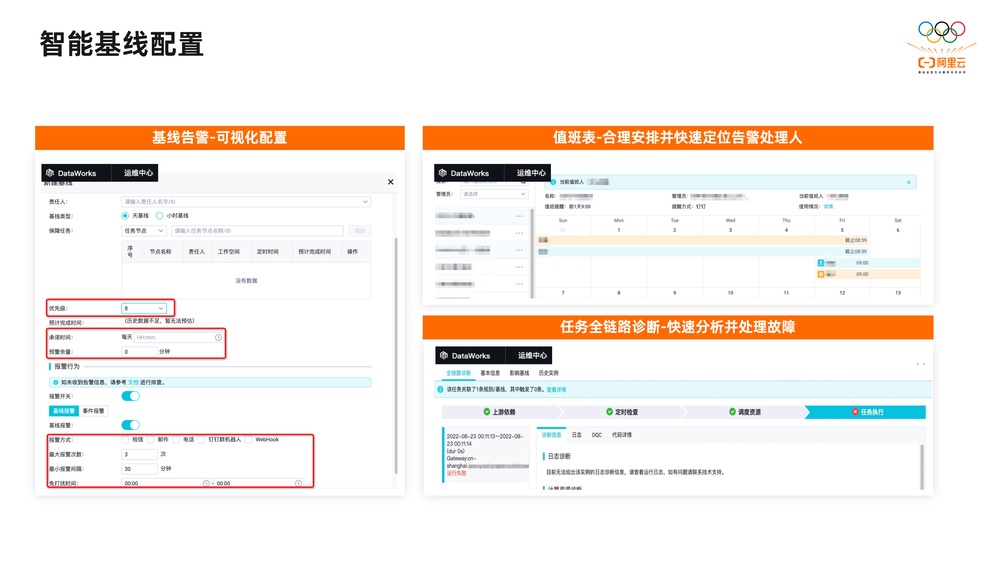
智能基线可以说是DataWorks中守护数据安全生产的核心功能,里面结合了DataWorks多项运维诊断和MaxCompute引擎能力。
1、智能分级调度与资源分配
当1个任务被设置1/3/5/7不同的基线等级后,整个平台运行的时候会按照优先级为核心数据产出进行重要性分级,高优先级任务及其上游,将获得更多的任务调度与MaxCompute的计算资源,以保障高优先级任务的运行资源。DataWorks也将其中涉及众多调度与资源分配的核心技术申请了国家专利。
2、智能预测与告警
1个核心任务可能会前置依赖多个任务,当我们在最终产出的任务节点配置基线后,前置的依赖任务就不需要再逐个配置运维告警了,将会极大提升运维效率。任务开始运行时,DataWorks会回溯依赖链路上所有任务的历史运行记录,同时结合平台当前运行及集群资源情况,每30秒刷新智能预测数据产出时间。例如设置核心任务期望产出时间基线在2:00,在核心链路中间,有个平时20:00产出的任务20:30仍未产生,结合当前集群水位情况,判断将会导致希望在2:00产出的最终核心任务延时,那么数仓同学将会在20:30就收到告警,提前干预处理延迟任务,而不是等到最终2:00任务已经延时了,才开始处理。
3、全链路智能诊断与排障
提前收到告警后,运维同学也会在DataWorks的运维中心处理告警任务, 在DAG图上查看上下游及每个周期实例的运行情况,通过运行诊断排查全链路上的告警问题,例如上游依赖告警、当前任务定时检查,调度资源检查、MaxCompute资源检查等等,可以快速定位并排障。

智能基线的配置及故障处理参考下方,针对任务责任人和值班人不同的情况,DataWorks还设置了值班表的功能,可以将不同责任人的告警消息统一推送给当前值班表对应人员。
以内部某个数仓团队为例,在稳定性治理之前,团队每周需要2.5人日进行值班,其中每年损失的不仅仅是135天的值班人日,凌晨起夜的同学135天日间的工作效率也会收到极大的影响,严重丧失工作的幸福感。稳定性治理之后,团队7级基线的破线率从每月的4次降低到了0次,值班同学起夜率从97%降低到了33%,同时极大地提升了员工的工作幸福感,这也是稳定性治理的重要意义。

小结
数据生产稳定性核心会用起夜率和基线破线率来衡量,通过围绕智能基线构建的全链路运维诊断能力来支持稳定性建设。智能基线可以基于集群当前水位,历史运行情况,智能分配计算与调度资源,让核心数据优先产出,并提供智能告警的能力方便提前干预处理。另外,稳定性的治理对于员工的工作幸福感也是非常大的提升。